近似强化学习和动态规划工具箱。包含各种具体实例和算法程序。非常有用。
”动态规划 动态规划_matlab 强化学习_matlab 近似动态规划“ 的搜索结果
使用Matlab / Octave的循环强化学习实施20210321更新:此仓库的PyTorch端口可在。 参考: 文件描述核心功能costFunction.m updateFt.m rewardFunction.m featureNormalize.m sharpRatio.m实用功能checkRRLGradient.m...
这段代码是值迭代算法的一个非常简单的实现,对于强化学习和动态规划领域的初学者来说,它是一个有用的起点。 随机清洁机器人 MDP:清洁机器人必须收集用过的罐子,还必须为电池充电。 状态描述了机器人的位置,...
【路径规划】基于强化学习Q-Learing实现栅格地图路径规划matlab源码.zip
动态规划算法(DPA)解决具有联合概率约束的问题。 它可用于解决路径规划问题,在这种情况下,碰到障碍物的机会必须保持在阈值以下。 该项目实现了本文[1],可以直接用于有效解决具有较大状态作用噪声空间的问题。 ...
软件X 17(2022)...万丹,15413,印度尼西亚ar t i cl e i nf o文章历史记录:2021年11月24日收到2022年1月15日收到修订版2022年1月25日接受保留字:动态规划最优控制动态优化强化学习a b st ra ct本文介绍了YADP


基本概念与理论,值迭代与策略迭代
译自强化学习工具包文档,加入自己的见解。本节所有Simulink模型均为Simulink内置模型,无需手动建立。这个样例展示了如何将watertank Simulink模型的PI控制器转换为强化学习DDPG代理。
机器⼈python路径规划_基于Q-learning的机器⼈路径规划系统 (matlab) 0 引⾔ Q-Learning算法是由Watkins于1989年在其博⼠论⽂中提出,是强化学习发展的⾥程碑,也是⽬前应⽤最为⼴泛的强化学习算法。Q- Learning⽬...


软件X 14(2021)100690原始软件出版物DynaProg:有限时间多阶段决策问题的确定性动态规划求解器FedericoMiretti,Daniela Misul,Ezio SpessaIC Engines Advanced Laboratory,Dipartimento Energia,Politecnico ...



@TOC 自适应动态规划学习笔记(3) 第三天 ADP的三个部分 &emnp;书接上回,上图展示了ADP的三个基本的组成,其中Critic Network输出对函数$J$的估计值
轨迹规划是在考虑临时或移动障碍物的前提下做出的规划,解决的是如何在避开障碍物的同时尽量沿着路径走的问题,和你看到地图上指示的路线后虽然是沿着路线走但是仍需要看路看车看人看红绿灯一样,重点在避障和遵守...
此示例显示了如何使用并行训练在Simulink®中训练深度Q学习网络(DQN)智能体以保持车道辅助(LKA)。 有关显示如何在不使用并行训练的情况下训练智能体的示例,请参阅 Train DQN Agent for Lane Keeping Assist。 ...
使用强化学习深度确定性策略梯度(DDPG)智能体。 水箱模型 此示例的原始模型是水箱模型。目的是控制水箱中的水位。 通过进行以下更改来修改原始模型: 删除PID控制器。 插入RL Agent块。 连接观察向量 [∫e...

使用DDPG训练摆锤系统打开模型并创建环境接口创建DDPG智能体训练智能体DDPG仿真 此示例显示了如何建立钟摆模型并使用DDPG训练。 模型加载参考我上一篇使用DQN的博文。 打开模型并创建环境接口 ...
强化学习智能体使用分别称为行动者和批评者表示的函数近似器来估计策略和价值函数。 行动者代表根据当前观察选择最佳行动的策略。 评论者代表价值函数,该函数估计当前保单的预期长期累积奖励。 在创建智能体之前,...
MATLAB中线性规划、非线性规划、整数规划、最大最小化模型的求解
0 引言Q-Learning算法是由Watkins于1989年在其博士论文中提出,是强化学习发展的里程碑,也是目前应用最为广泛的强化学习算法。Q- Learning目前主要应用于动态系统、机器人控制、工厂中学习最优操作工序以及学习棋类...

基于深度强化学习的贪吃蛇游戏是一种将人工智能与经典游戏相结合的应用。其中,深度强化学习是一种通过智能体与环境的交互来学习最优策略的方法,而贪吃蛇游戏是一种经典的游戏,玩家通过操控蛇的移动来获取食物并...
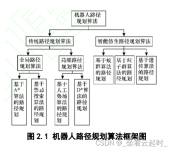
科技经济信息化 科技经济导刊 2019,27(05) Technology and Economic Guide 移动机器人路径规划指的是在一个具有障碍物的环境中寻找一条从起始状态到目标状态的无碰撞最优路径或近似最优路径。通常,移动机器人路径...
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地